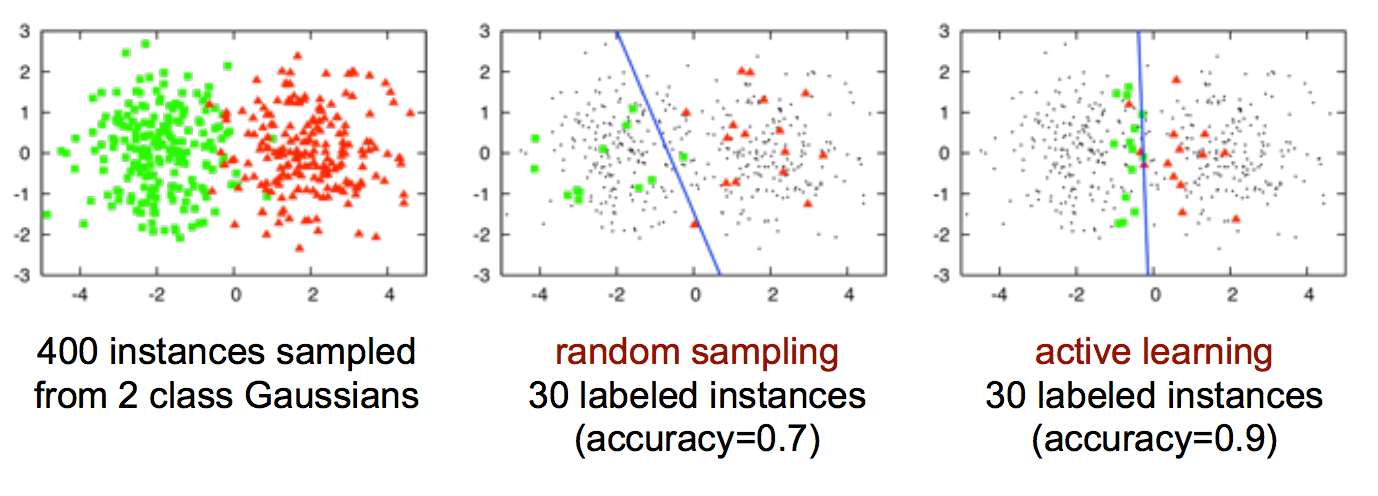
Active Learning is a form of Semi-supervised machine learning meaning models are trained using both labeled and unlabeled data.
The goal of this iterative learning approach is to speed along the learning process, especially if you don’t have a large labeled dataset to practice traditional supervised learning methods.The process of active learning involves the prioritization of which data out of the dataset should be labelled for training the model. Essentially, the model gets to proactively choose which data it wants to learn from.
https://miro.medium.com/max/1400/1*YnnQz4XrW5_eQ4mbizuRSw.png
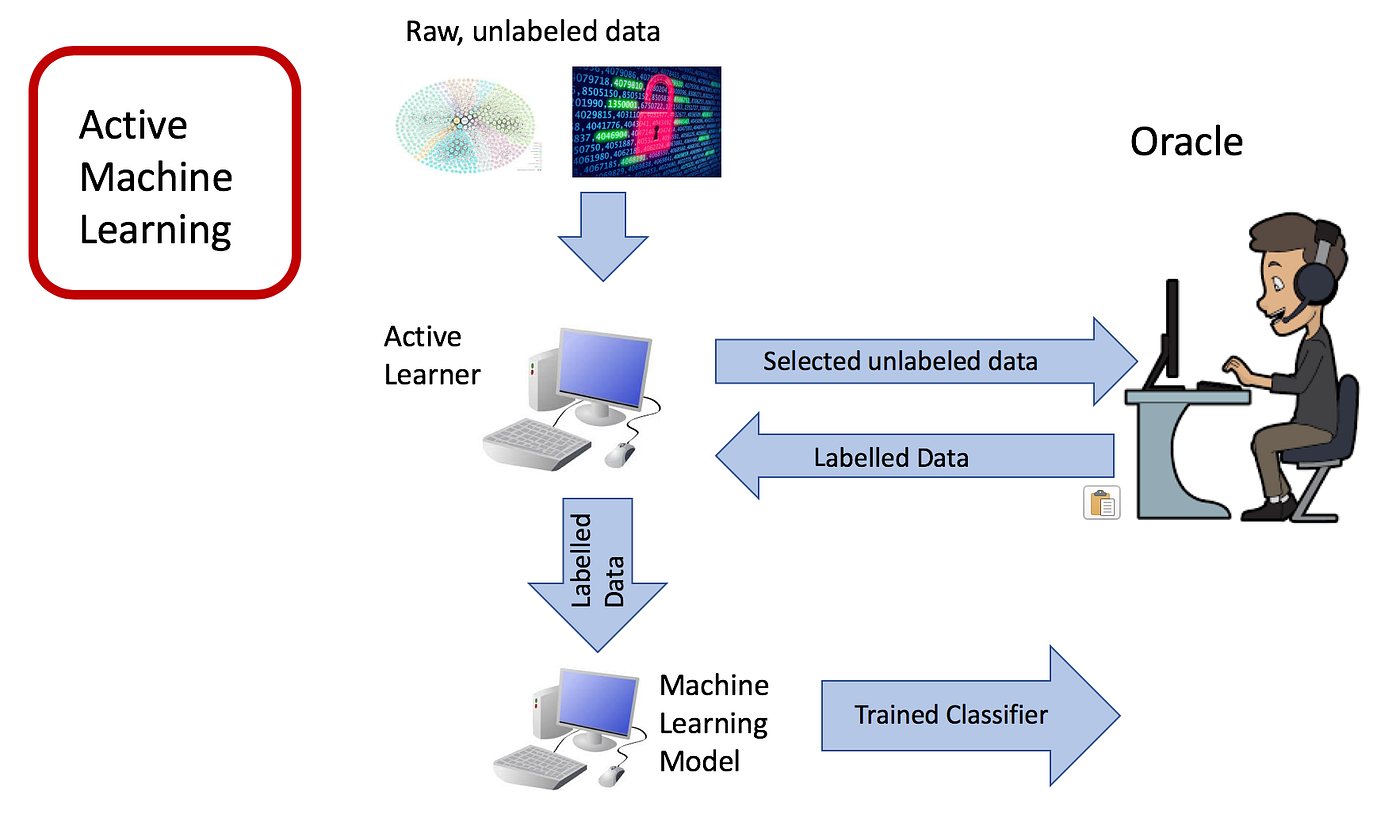
The most popular one is known as pool-based sampling, here we see how it works
- A person (known in this process as the oracle) labels a small subset of the dataset and provides that labeled data to the model.
- The model (known as the active learner) processes that data and predicts the classes of the unlabeled data points with a certain confidence level.
- Assuming that initial prediction is below the desired accuracy and confidence levels, a sampling technique is then used to determine what the next subset of data to be labeled will be.
- People label the selected subset of data and send it back to the model for processing.
- The process continues until the model’s predictions are at the required confidence and accuracy levels.
There are three categories of active learning:
- Stream-based selective sampling
- Pool-based sampling
- Membership query synthesis
Stream-based selective sampling
In this scenario, the algorithm determines if it would be beneficial enough to query for the label of a specific unlabeled entry in the dataset. While the model is being trained, it is presented with a data instance and immediately decides if it wants to query the label. This approach has a natural disadvantage that comes from the lack of guarantee that the data scientist will stay within budget.
Pool-based sampling
This is the commonly use category in active learning. In this sampling method, the algorithm attempts to evaluate the entire dataset before it selects the best query or set of queries. The active learner algorithm is often initially trained on a fully labeled part of the data which is then used to determine which instances would be most beneficial to insert into the training set for the next active learning loop. The downside of this method is the amount of memory it can require.
Membership query synthesis
This method is rarely use case , because it involves the generation of synthetic data. The active learner in this method is allowed to create its own examples for labeling. This method is compatible with problems where it is easy to generate a data instance.
When to Choose an Active Learning Approach
- Your AI solution has no time to manually labeling data
- If you don’t have enough budget to label data manually(by person)
- If you have large pool of unlabeled data
- You have people unavailability to manually label
Thank you.

{kind=link}
{kind=link}